

数据库基础
主键、索引、外键
1、什么是主键
主键是一列,其值可以唯一标识表中的每一行数据,每个表只能有一个主键,而且主键的值不能重复,也不能包含NULL值,通常用来保证数据的唯一性和用于在表中查找特定的行。
2、主键、外键、索引的区别
定义:
主键:唯一标识一条记录,不允许重复,不允许为空 外键:外键是一个表中的字段,其值是另一个表的主键,用于建立两个表之间的关系。
索引:没有重复值,但可以有一个空值 ,用于快速查询到数据。
作用:
主键:用于唯一标识表中每一行的字段
外键:主要用于和其它表建立联系 索引:为了提高查询排序的速度
区别:
外键是一个表中的字段,它与另一个表的主键形成关联,用于建立表之间的关系。
主键和外键通常都与索引有关,但索引不一定是主键或外键。
一条SQL查询语句是如何执行的?
简要回答
- 连接阶段:由服务器端的连接器组件负责,在客户端与 MySQL 服务器之间建立连接,并验证用户权限。
- 查询缓存(仅限 MySQL 8.0 前):检查是否命中缓存,若有完全相同且有效的查询结果可以直接返回。
- 解析与预处理:解析 SQL 语法,检查语法是否正确,并生成抽象语法树,然后,预处理器进行一些语义检查,验证表和字段是否存在。
- 优化器:基于统计信息和成本模型,考虑多种执行方案,并选择最优执行计划(如索引选择、JOIN 顺序)。
- 执行器:根据选择的执行计划,调用存储引擎接口,并按执行计划读取数据并处理(排序、聚合等)。
- 存储引擎(如 InnoDB):负责从磁盘或内存读取数据,返回给执行器。
- 返回结果:执行器进行必要的处理(如过滤、排序)后,将结果集返回客户端,可能分批次传输。
详细回答
- 连接阶段:
- 当我们在客户端(如命令行工具、应用程序)输入并执行一条 SQL 查询时,首先需要与数据库服务器建立一个网络连接。
- 这个过程包括 TCP/IP 协议的三次握手,以及数据库层面的认证,比如验证用户名和密码。
- 连接成功后,服务器会为这个连接分配一个独立的线程来处理后续的请求。
- 查询缓存(MySQL 8.0 前):
- 服务器接收到 SQL 语句后,会先检查 查询缓存。这是一个位于内存中的区域,存储了之前执行过的查询语句及其结果。
- 如果当前查询与缓存中的某个查询完全一致(包括 SQL 语句本身、连接的数据库、客户端的协议版本等),并且缓存仍然有效(比如涉及的表没有被修改),那么服务器会直接从缓存中返回结果,无需执行后续的解析、优化和执行过程。
- 需要注意的是,在 MySQL 8.0 及更高版本中,查询缓存功能已经被移除。 这是因为在并发写入场景下,查询缓存的维护成本很高,容易成为性能瓶颈。因此,在现代数据库系统中,通常不再依赖查询缓存进行优化。
- 解析与预处理:
- 如果查询缓存未命中,服务器会将 SQL 查询语句发送给解析器。解析器会对 SQL 语句进行词法分析(将语句分解成一个个词法单元,如关键字、标识符、操作符等) 和 语法分析(根据 SQL 语法规则检查语句是否合法,生成一个抽象语法树 AST)。
- 如果语法有错误,解析器会直接返回错误信息。如果语法没问题,预处理器根据抽象语法树,进一步检查 SQL 语句的合法性,例如,检查表名、字段名是否存在,是否有权限执行该查询等,它还会进行一些语义上的检查和转换。
- 优化器:
- 优化器的目标是找到执行查询的最优执行计划。它会考虑多种可能的执行方式,并评估它们的成本(如 I/O 次数、CPU 消耗等)。
- 优化器会利用统计信息(如表的大小、索引的选择性等)来做出决策。
- 常见的优化策略包括: ① 选择合适的索引。 ② 决定表的连接顺序。 ③ 选择合适的连接算法(如嵌套循环连接、哈希连接、合并排序连接)。 ④ 改写查询语句,使其更高效。
- 最终,优化器会生成一个最优的执行计划(Execution Plan),它描述了如何执行查询的步骤。
- 执行器:
- 执行器根据优化器生成的执行计划,调用存储引擎的接口来执行查询。
- 执行器会按照执行计划的步骤,从存储引擎获取数据,进行过滤、排序、连接等操作。例如,如果执行计划指示使用某个索引进行查找,执行器就会调用存储引擎的索引查找接口。
- 执行器会逐步处理数据,并将结果返回给客户端。
- 存储引擎(以 InnoDB 为例):
- 存储引擎是数据库系统中负责数据存储和检索的核心组件。不同的存储引擎有不同的特点和优势(如 InnoDB、MyISAM 等)。
- 执行器通过存储引擎的 API 来访问和操作数据文件。
- 存储引擎负责数据的读取、写入、更新、删除以及事务管理、锁机制等。
- 返回结果:
- 执行器将最终的查询结果返回给客户端。
- 客户端应用程序接收到结果后,可以进行进一步的处理和展示。
知识拓展
- MySQL执行一条SQL查询语句的流程示意图(以MySQL8.0为例),如下所示:
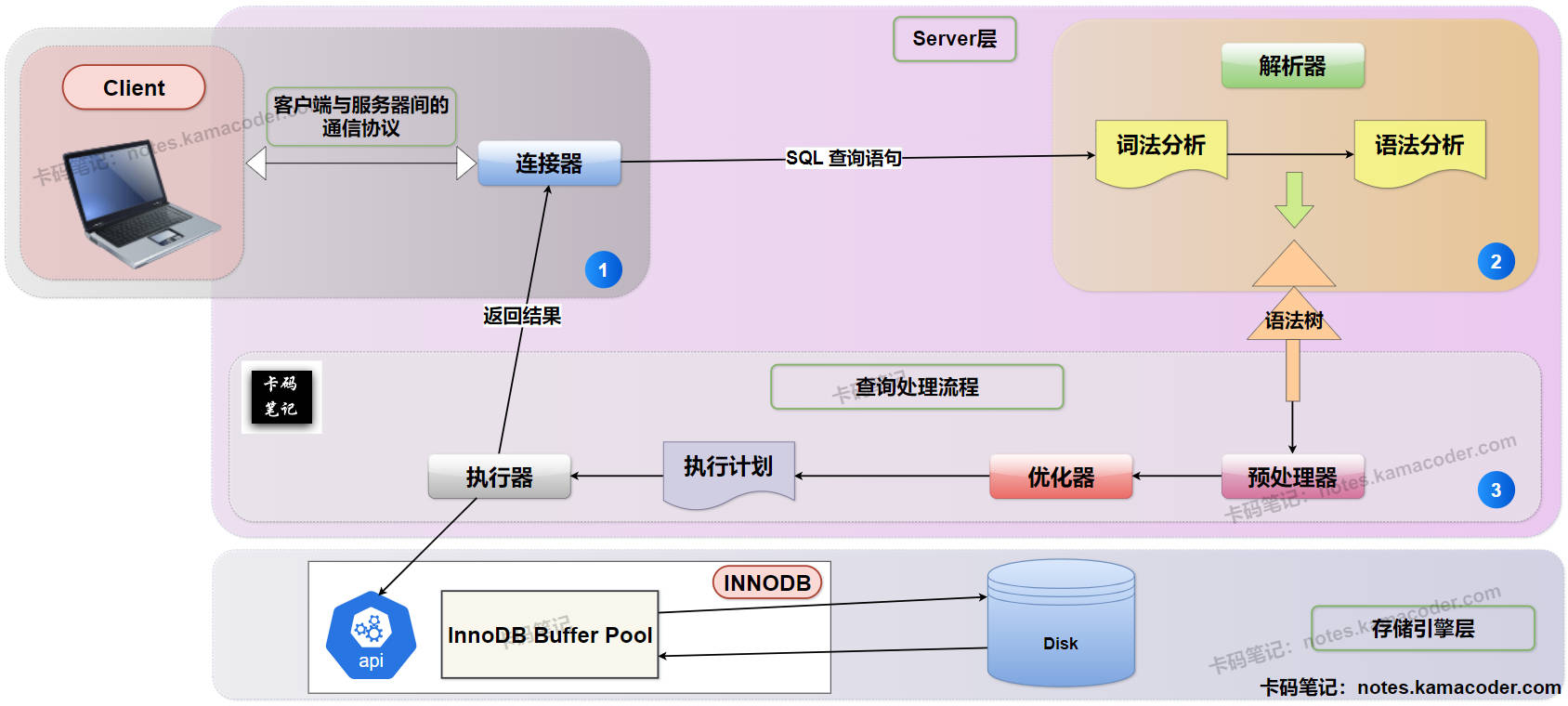
- 面试官可能的追问1—为什么 MySQL 8.0 移除了查询缓存?
- 答:缓存失效频繁(表更新即失效),维护成本高且命中率低。现代优化器能生成更高效执行计划,且应用层缓存(如 Redis)更灵活。
- 面试官可能的追问2—优化器如何决定使用某个索引?
- 答:基于索引的选择性(唯一性)、统计信息(基数)和查询条件。可通过
EXPLAIN查看possible_keys和key字段。
- 答:基于索引的选择性(唯一性)、统计信息(基数)和查询条件。可通过
- 面试官可能的追问3—如何分析一条慢 SQL 的执行瓶颈?
- 答: ① 使用
EXPLAIN查看执行计划(索引使用、扫描行数)。 ② 开启慢查询日志(slow_query_log)捕获耗时操作。 ③ 检查锁竞争(SHOW ENGINE INNODB STATUS)。
- 答: ① 使用
解释一下SQL中的JOIN操作?
简要回答
SQL中的JOIN操作用于将来自两个或多个表的数据根据某些条件结合在一起。常见的JOIN类型有:
- INNER JOIN:返回两个表中匹配的记录。
- LEFT JOIN(或LEFT OUTER JOIN):返回左表所有记录以及右表中匹配的记录,右表没有匹配的则用NULL填充。
- RIGHT JOIN(或RIGHT OUTER JOIN):返回右表所有记录以及左表中匹配的记录,左表没有匹配的则用NULL填充。
- FULL JOIN(或FULL OUTER JOIN):返回左表和右表中所有记录,匹配的部分显示实际数据,未匹配的部分显示NULL。
- CROSS JOIN:返回两个表的笛卡尔积,即每一行与另一表的每一行进行组合。
解释一下数据库的三大范式?
简要回答
数据库的三大范式(1NF、2NF、3NF)是为了减少数据冗余和避免异常操作而设计的规范。它们分别是:
- 第一范式(1NF):要求数据表中的每个字段只能包含原子值。
- 第二范式(2NF):要求满足 1NF,并且所有非主属性完全依赖于主键。
- 第三范式(3NF):要求满足 2NF,并且每个非主属性直接依赖于主键,而不通过其他非主属性间接依赖。
详细回答
1. 第一范式(1NF)
- 定义:数据库表中的每列必须是原子性的,即每个字段的值不可再分。
- 要求:
- 每个字段的数据都是不可再分的基本数据项(如字符串、整数等)。
- 表格的每个字段都应该包含一个单一的值(不允许出现集合、数组等复杂数据类型)。
- 例子:
- 如果一个表格有一个字段“电话号码”,这个字段中不能存储多个电话号码(如
1234567890, 9876543210),而应该将其拆分为多个字段或多行。 不符合 1NF 的例子: |用户ID|用户名|电话号码| |:-:|:-:|:-:| |1|张三|1234567890, 9876543210| |2|李四|1122334455| 符合 1NF 的例子: |用户ID|用户名|电话号码| |:-:|:-:|:-:| |1|张三|1234567890| |1|张三|9876543210| |2|李四|1122334455|
- 如果一个表格有一个字段“电话号码”,这个字段中不能存储多个电话号码(如
2. 第二范式(2NF)
- 定义:数据库表满足 1NF,并且所有非主属性完全依赖于主键。也就是说,消除部分依赖。
- 要求:
- 表格的所有非主键列必须完全依赖于主键,而不是依赖于主键的一部分。
- 对于复合主键(即主键由多个字段组成的情况),如果某些非主属性只依赖于主键的部分字段,则违反了 2NF。
- 例子: 假设有一个表格存储学生和课程的成绩,其中表格的主键是(学生ID,课程ID),如果学生的姓名也出现在表格中,那么姓名只依赖于学生ID,而不依赖于课程ID,这就是部分依赖,违反了 2NF。 不符合 2NF 的例子:学生ID课程ID姓名成绩1101张三901102张三802101李四852103李四88这里,“姓名”字段仅依赖于
学生ID,而与课程ID无关,因此“姓名”是部分依赖。符合 2NF 的例子(拆分为两个表):- 学生表:学生ID姓名1张三2李四
- 成绩表:学生ID课程ID成绩110190110280210185210388
3. 第三范式(3NF)
- 定义:数据库表满足 2NF,并且所有非主属性不依赖于其他非主属性(即消除传递依赖)。
- 要求:
- 表格中的非主属性不应该依赖于其他非主属性,而应直接依赖于主键。
- 如果存在某个非主属性A依赖于另一个非主属性B,并且B依赖于主键,那么B不应出现在同一个表中。
- 例子: 假设有一个表格存储员工的ID、部门ID、部门名称、员工姓名和工资。如果部门名称依赖于部门ID,那么它是间接依赖于员工ID(主键),违反了 3NF。 不符合 3NF 的例子:员工ID员工姓名部门ID部门名称工资1张三101人力资源部50002李四102技术部60003王五101人力资源部5500这里,
部门名称依赖于部门ID,而部门ID又依赖于员工ID,因此存在传递依赖,违反了 3NF。符合 3NF 的例子(拆分为三个表):- 员工表:员工ID员工姓名部门ID工资1张三10150002李四10260003王五1015500
- 部门表:部门ID部门名称101人力资源部102技术部
什么是数据库的分片和分区?有什么区别?
分片(Sharding):
- 概念:分片是将数据水平切分到多个独立的数据库实例或服务器上,每个分片存储数据的一个子集。
- 应用场景:适用于大规模分布式系统,提升数据库的扩展性和性能。
- 特点:- 数据分布在不同的物理节点上。
- 每个分片通常有独立的存储和计算资源。
分区(Partitioning):
- 概念:分区是将单个数据库表的数据按照某种规则划分成多个部分,每个部分称为一个分区,所有分区仍然在同一个数据库实例中。
- 应用场景:适用于管理和查询大表,提升查询性能和维护效率。
- 特点:- 分区在同一个数据库实例内。
- 分区之间共享数据库的资源。
区别:
- 范围:分片涉及多个数据库实例或服务器,分区则是在单个数据库实例内。
- 目的:分片主要用于扩展数据库的容量和处理能力,分区主要用于优化大表的管理和查询性能。
- 复杂性:分片通常比分区更复杂,需要处理数据分布、路由等问题,而分区则相对简单。
什么是数据库的连接池?为什么要使用连接池?
数据库连接池是管理数据库连接的技术,当需要建立数据库连接时,会从连接池中获取可用的连接,而不直接创建连接。
- 降低频繁创建销毁数据库连接带来的开销
- 数据库连接池可以设置最大连接数量,能够限制应用程序对数据库系统的并发访问,提高系统稳定性
什么是数据库的外键?有什么作用?
数据库的外键是一个表中的字段,它引用了另一个表的主键。
外键的主要作用是维护数据库中表之间的数据一致性,确保引用关系的完整性。
外键的性能影响:外键约束会增加数据库的管理和检查开销,尤其是在进行插入、更新或删除操作时,会增加额外的检查操作。因此,在高性能要求的系统中,外键有时会被禁用。
MySQL和Redis的区别?
mysql是关系型数据库,基于磁盘存储,底层是表、行、列结构,事务性完备ACID, redis是键值对数据库,基于内存,底层有多种数据结构:String、hash、LIst、set、zset ,事务功能一般;
mysql持久化机制主要靠redolog实现,基于innoDB存储引擎,适用于处理复杂查询、事务处理、大量数据集的场景 redis持久化机制主要靠AOF和RDB快照实现,读写速度效率很高,
解释一下数据库的备份和恢复策略?
数据库的备份是指将数据库的数据复制并存储在安全的地方,以防止数据丢失或损坏。恢复策略则是在数据丢失或损坏后,使用备份来还原数据库到某个一致的状态。
备份策略通常包括:
全备份:定期复制整个数据库。
增量备份:只复制自上次全备份或增量备份后有变化的数据。
差异备份:复制自上次全备份后有变化的数据。
恢复策略通常包括:
完全恢复:使用全备份和所有相关的增量备份来还原数据库。
部分恢复:只恢复受损的部分数据。
时间点恢复:将数据库还原到特定的时间点。
简单来说,备份策略是确保数据安全,恢复策略是在数据受损时能够快速恢复数据。
可以对数据库表做那些优化?
- 合理使用数据库分表
对于一些特别大的表,可以考虑将其拆分成多个子表,从而更好地管理数据。
- 建立索引
在经常被查询的列上建立索引,提高查询性能。但是也要注意过多的索引影响插入、更新和删除的性能。
- 避免使用
Select *
只选择需要的列而不是使用SELECT *
- 选择合适的数据类型
- 尽量使用TINYINT,SMALLINT,MEDIUM_INT替代INT类型,如果是非负则加上UNSIGNED
VARCHAR的长度只分配真正需要的空间- 尽量使用整数或者枚举替代字符串类型
- 时间类型尽量使用
TIMESTAMP而非DATETIME - 单表不要放太多字段
- 尽量少使用NULL,很难查询优化而且占用额外索引空间
了解MongoDB嘛,它和MySQL有哪些区别
数据库模型 MySQL:关系型数据库,数据以表格的形式存储,每个表包含多个行和列,其中每一行是一个记录。 MongoDB:非关系型数据库(文档型数据库),数据以BSON(Binary JSON)文档的形式存储,文档可以包含嵌套结构和数组。每个文档都有一个唯一的_id字段作为主键。
查询语句 MySQL:使用结构化查询语言(SQL)进行查询 MongoDB:使用MongoDB自己的查询方式
模式设计
MySQL: MySQL是有模式的数据库,表结构需要在设计时明确定义,包括字段名、数据类型。
MongoDB: MongoDB是无模式的数据库,文档可以根据需要动态添加字段,没有固定的表结构。
存储引擎
MySQL:MySQL支持多种存储引擎,如InnoDB、MyISAM等,每个引擎有不同的特性和适用场景。
MongoDB: MongoDB使用存储引擎WiredTiger,默认提供高性能的读写能力和压缩特性。
适用场景
MySQL: 适用于需要处理结构化数据,支持事务处理和复杂查询的应用。
MongoDB: 适用于需要处理大量非结构化或半结构化数据
扩展性 MySQL: 通常使用主从复制和垂直分区来实现扩展性。
MongoDB: 具有较好的横向扩展性,通过分片可以在多台机器上分布数据。
总结:如果数据是结构化的且需要复杂的事务支持,MySQL更适合;如果数据是非结构化或半结构化的,且需要横向扩展性,MongoDB更适合。
Comments NOTHING